risorse | perceptron in scratch
Ho provato a realizzare in Scratch un neurone artificiale, lo storico percettrone di Rosenblatt:

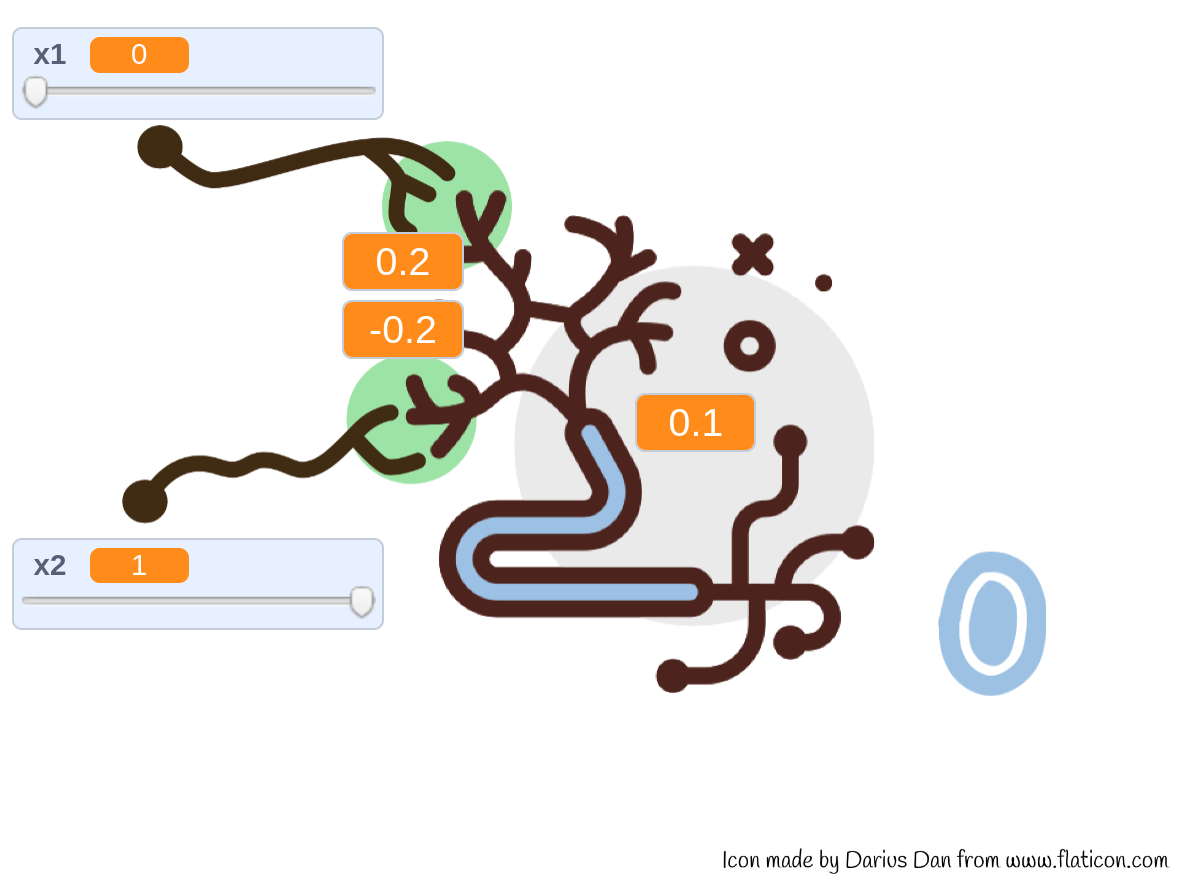
Schema di un neurone artificiale (disegno di Darius Dan scaricato da www.flaticon.com).
Il neurone artificiale, il cui nucleo è detto soma, riceve gli stimoli dall'ambiente circostante attraverso delle sottili ramificazioni dette dendriti. Se il livello degli stimoli supera una certa soglia il neurone si attiva e propaga a sua volta un impulso elettrico che raggiunge i neuroni adiacenti attraverso un particolare suo prolungamento, l'assone. Le connessioni tra assone e dendriti sono modulate dalle sinapsi che possono avere un effetto eccitatorio o inibitorio, vale a dire possono amplificare o attenuare il segnale che le attraversa.
Per ridurre al minimo la complessità del codice il neurone riceve due soli stimoli, x1 e x2. L'effetto di modulazione delle sinapsi (rappresentate dalle aree verdi nello schema sottostante) è ottenuto per mezzo di due fattori moltiplicativi detti pesi, w1 e w2. Il valore combinato del segnale d'ingresso del neurone è quindi:
input = x1·w1 + x2·w2
Se il segnale in ingresso supera la soglia θ (theta) il neurone si attiva portando l'uscita a 1; se invece gli stimoli ricevuti non sono tali da eccitarlo il neurone risponde con uno 0:
output = | 1 se input > θ |
| 0 se input ≤ θ |
Il percettrone completo.
Il programma del percettrone contempla quindi:
I valori dei pesi sono visibili nelle vicinanze delle rispettive sinapsi mentre il valore della soglia interna è mostrato al centro del neurone. In basso a destra si trova lo sprite che indica il livello di attivazione del neurone.
Per ragioni matematiche che non è opportuno approfondire in questa sede è bene che i valori iniziali delle variabili w1, w2 e theta siano prossimi allo zero. Di norma il loro valore è scelto a caso, in questo caso sono stati loro attribuiti dei valori arbitrari:
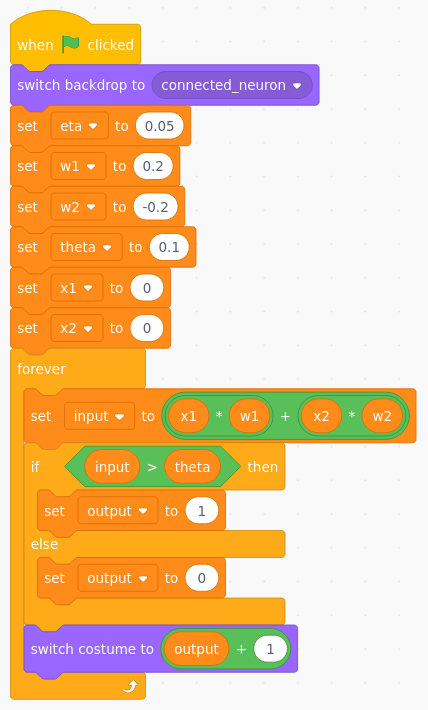
Il codice che riproduce il funzionamento del neurone artificiale.
Trascurando per il momento la variabile eta, il cui scopo diverrà chiaro più avanti, il frammento di codice che riproduce il funzionamento del neurone artificiale rispecchia fedelmente quanto fin qui anticipato. È facile verificare sperimentalmente che la risposta del neurone cambia in funzione del valore assunto dalle variabili di ingresso. Quali siano le configurazioni di x1 e x2 che fanno eccitare il neurone dipende dal valore dei pesi e della soglia.
Il percettrone è dotato di una certa capacità di adattamento: se la risposta fornita non è quella desiderata si interviene sui pesi w1 e w2 e sul valore della soglia theta in modo da indurre il neurone a modificare il suo comportamento.
L'algoritmo di apprendimento del percettrone è piuttosto semplice nella sua formulazione, non altrettanto la sua giustificazione matematica, che per tale ragione viene omessa. Indicato con target la risposta desiderata, pesi e soglia vanno così modificati:
w1 ← w1 + η·(target - output)·x1
w2 ← w2 + η·(target - output)·x2
θ ← θ - η·(target - output)
Il parametro η (eta), detto anche tasso di apprendimento, è un fattore moltiplicativo positivo prossimo allo zero il cui scopo è quello di ottimizzare l'apprendimento cercando il giusto compromesso tra efficienza e accuratezza.
Se target=output, cioé se il percettrone si comporta come atteso, pesi e soglia restano invariati. Se il neurone non si è attivato quando previsto (output=0, target=1) allora i pesi subiscono un incremento proporzionale allo stimolo e la soglia abbassata:
w1 ← w1 + η·x1
w2 ← w2 + η·x2
θ ← θ - η
Di converso, se il neurone si è attivato quando non desiderato (output=1, target=0), le correzioni a pesi e soglia cambiano di segno:
w1 ← w1 - η·x1
w2 ← w2 - η·x2
θ ← θ + η
L'apprendimento viene attivato dal click sullo sprite principale:
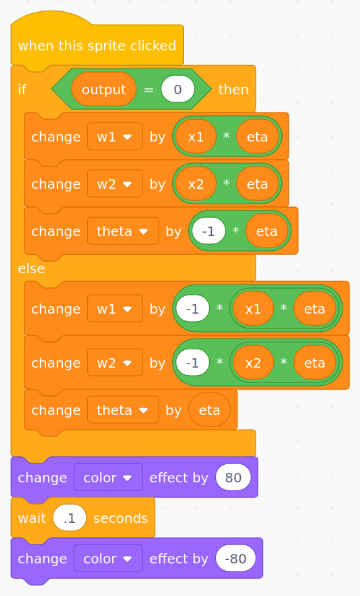
Il codice dell'apprendimento del neurone artificiale.
Intuitivamente l'algoritmo di apprendimento del percettrone si spiega considerando il caso in cui il neurone non si è attivato quando previsto. Per aumentare le probabilità di far eccitare il neurone si può agire su due fronti: aumentare il livello del segnale in ingresso oppure diminuire la soglia di attivazione. L'algoritmo di apprendimento interviene su entrambi. Il segnale di ingresso in origine vale:
input = x1·w1 + x2·w2
mentre con i pesi aggiornati il suo valore diventa:
input' = x1·(w1 + η·x1) + x2·(w2 + η·x2)
input' = x1·w1 + η·x12 + x2·w2 + η·x22
input' = x1·w1 + x2·w2 + η·x12 + η·x22
input' = input + η·x12 + η·x22
Essendo η positivo anche i termini η·x12 e η·x22 sono positivi e dunque complessivamente il segnale in ingresso è aumentato, a parità di stimoli. Inoltre, poiché l'algoritmo abbassa il valore di θ, seppure di una minima quantità:
θ ← θ - η
complessivamente la probabilità che il neurone si ecciti quando in futuro riceverà gli stessi stimoli aumenta. Considerazioni analoghe si possono fare per il caso in cui il neurone si è attivato quando non previsto: l'apprendimento causa la diminuzione del segnale d'ingresso e l'aumento del valore soglia, riducendo così la probabilità che il neurone si ecciti quando riceve gli stessi stimoli.
La funzione or prevede che il neurone si attivi quando almeno uno dei due stimoli vale 1:
| x1 | x2 | or |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
| 0 | 1 | 1 |
Per addestrare il percettrone occorre presentargli ciclicamente le combinazioni d'ingresso 00, 10, 11, 01 e innescare l'apprendimento nel caso la risposta ottenuta non corrisponda al risultato atteso. L'addestramento non è istantaneo: in genere sono necessari diversi cicli di apprendimento — epoche, nel gergo delle reti neurali — affinché il sistema impari a rispondere correttamente a tutti gli stimoli. Con i valori iniziali proposti per i pesi w1 e w2, la soglia θ e il tasso di apprendimento η sono sufficienti 5 cicli per raggiungere l'infallibilità:
L'apprendimento si attiva con un click sullo sprite che rappresenta la risposta del percettrone; ricordarsi che va attuato solo se la risposta del sistema non è quella corretta.
| epoca | x1 | x2 | output | target | w1 | w2 | θ |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0.20 | -0.20 | 0.10 | |
| 1 | 1 | 0 | 1 | 1 | 0.20 | -0.20 | 0.10 |
| 1 | 1 | 0 | 1 | 0.25 | -0.15 | 0.05 | |
| 0 | 1 | 0 | 1 | 0.25 | -0.10 | 0.00 | |
| 0 | 0 | 0 | 0 | 0.25 | -0.10 | 0.00 | |
| 2 | 1 | 0 | 1 | 1 | 0.25 | -0.10 | 0.00 |
| 1 | 1 | 1 | 1 | 0.25 | -0.10 | 0.00 | |
| 0 | 1 | 0 | 1 | 0.25 | -0.05 | -0.05 | |
| 0 | 0 | 1 | 0 | 0.25 | -0.05 | 0.00 | |
| 3 | 1 | 0 | 1 | 1 | 0.25 | -0.05 | -0.05 |
| 1 | 1 | 1 | 1 | 0.25 | -0.05 | -0.05 | |
| 0 | 1 | 0 | 1 | 0.25 | 0.00 | -0.05 | |
| 0 | 0 | 1 | 0 | 0.25 | 0.00 | 0.00 | |
| 4 | 1 | 0 | 1 | 1 | 0.25 | 0.00 | 0.00 |
| 1 | 1 | 1 | 1 | 0.25 | 0.00 | 0.00 | |
| 0 | 1 | 0 | 1 | 0.25 | 0.05 | -0.05 | |
| 0 | 0 | 1 | 0 | 0.25 | 0.05 | 0.00 | |
| 5 | 1 | 0 | 1 | 1 | 0.25 | 0.05 | 0.00 |
| 1 | 1 | 1 | 1 | 0.25 | 0.05 | 0.00 | |
| 0 | 1 | 1 | 1 | 0.25 | 0.05 | 0.00 | |
| 0 | 0 | 0 | 0 | 0.25 | 0.05 | 0.00 | |
| 6 | 1 | 0 | 1 | 1 | 0.25 | 0.05 | 0.00 |
| 1 | 1 | 1 | 1 | 0.25 | 0.05 | 0.00 | |
| 0 | 1 | 1 | 1 | 0.25 | 0.05 | 0.00 |
L'apprendimento della funzione or.
La tabella riporta le fasi dell'addestramento del percettrone: in rosso sono evidenziati gli errori compiuti dal sistema e l'effetto correttivo dell'apprendimento sui pesi w1, w2 e sulla soglia θ. I valori ottimali cui l'algoritmo è pervenuto sono:
| w1 | = | 0.25 |
| w2 | = | 0.05 |
| θ | = | 0.00 |
Il percettrone è un sistema versatile. Una volta acquisita la capacità di replicare la funzione or può essere rapidamente riconfigurato per replicare una funzione diversa, per esempio l'and:
| x1 | x2 | and |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
| 0 | 1 | 0 |
In questo caso sono sufficienti 4 cicli per completare con successo l'apprendimento.
Un'altra funzione da sperimentare è not x1:
| x1 | x2 | not x1 |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 0 | 0 |
| 1 | 1 | 0 |
| 0 | 1 | 1 |
La transizione and/not x1 si compie in 5 cicli.
Il percettrone non è in grado di imparare qualunque funzione, ad esempio non è in grado di replicare la funzione xor, quella che prevede che il neurone si attivi nel caso in cui uno solo degli stimoli sia presente. Nel 1969 Marvin Minsky e Samuel Papert (lo stesso Papert che nel 1985 fondò il MIT Media Lab dove nel 2003 nacque Scratch!) utilizzarono proprio questa funzione per dimostrare nel loro celebre libro Perceptrons: an introduction to computational geometry i limiti teorici del percettrone.
| x1 | x2 | xor |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
| 0 | 1 | 1 |
Chi intende cimentarsi nel tentativo di insegnare al percettrone la funzione xor è bene che si armi di gran pazienza, perché… non ci riuscirà mai!
Il percettrone è un classificatore lineare, vale a dire che taglia in due lo spazio delle configurazioni degli stimoli in ingresso e risponde 0 o 1 a seconda che la configurazione corrente si trovi da una parte o dall'altra del taglio. Per chiarire meglio il concetto si consideri la rappresentazione grafica della funzione or sul piano cartesiano. La configurazione per la quale la risposta attesa è 0 è indicata in rosso, le altre in verde:
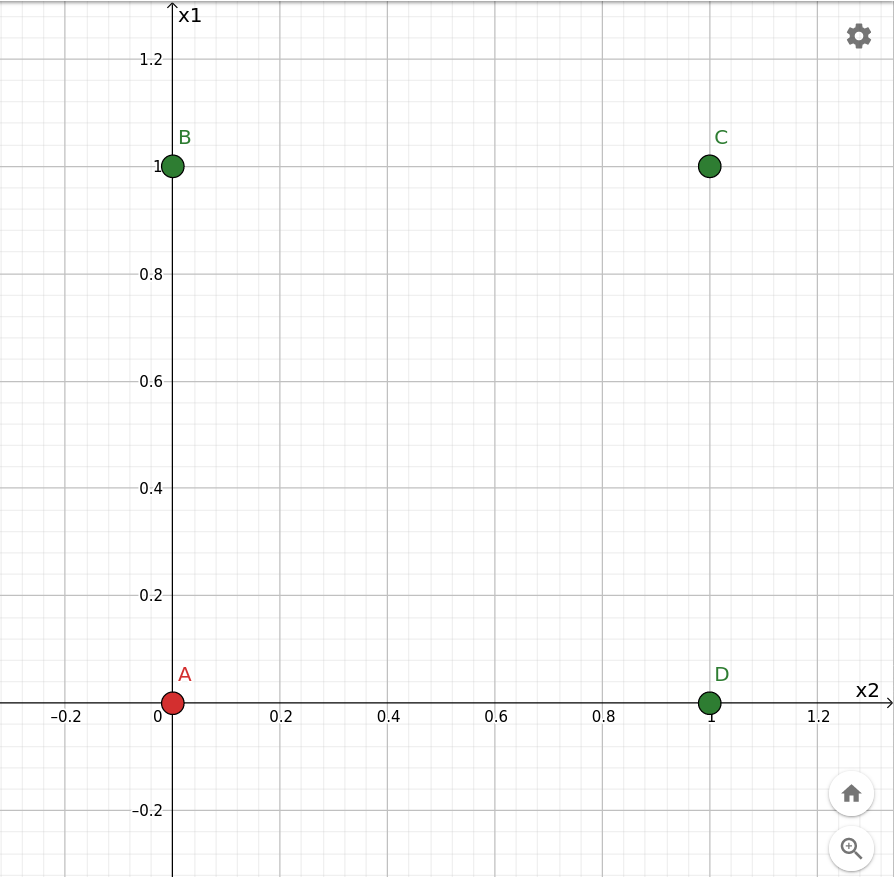
Rappresentazione geometrica della funzione or.
Se sullo stesso grafico si evidenzia il semipiano:
p: x1·w1 + x2·w2 > θ
dopo aver sostituito i parametri con i rispettivi valori iniziali:
p: x1·0.20 - x2·0.20 > 0.10
si ottiene:
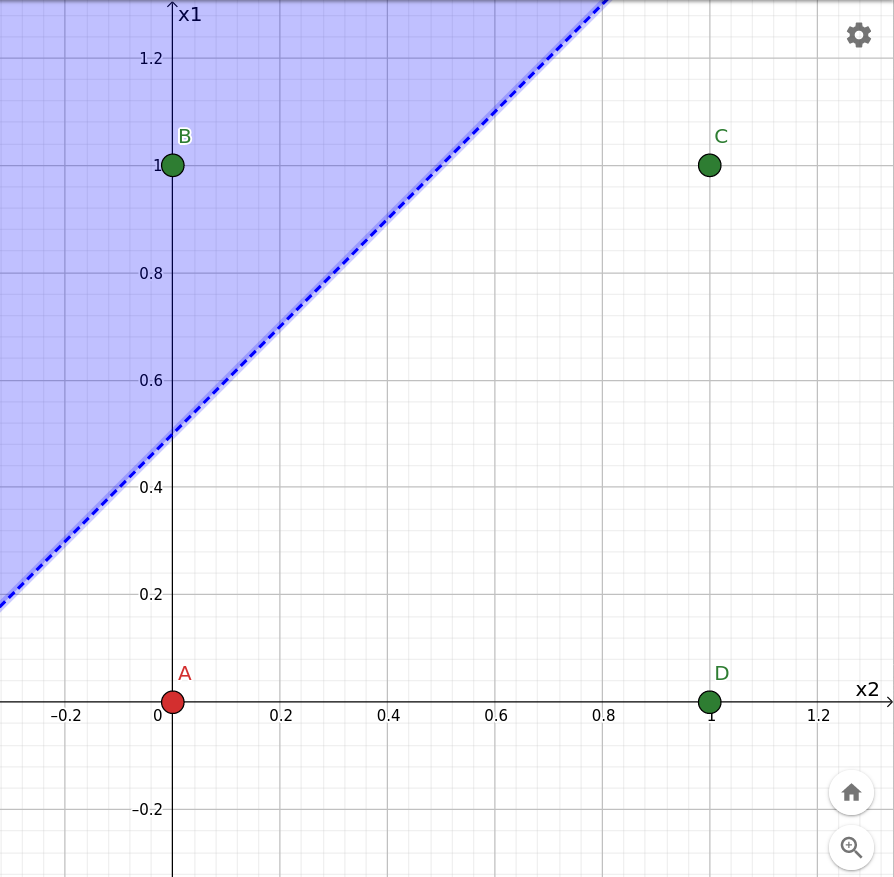
Il taglio iniziale prodotto dal percettrone.
Ciò conferma quanto sperimentato nel primo ciclo di apprendimento, durante il quale il percettrone si è attivato solo per la configurazione x1=1, x2=0 (punto B sul grafico).
L'effetto dell'apprendimento è quello di ricollocare il taglio nel tentativo di separare le configurazioni verdi da quelle rosse. L'animazione sottostante mostra l'evoluzione del taglio all'avanzare dell'addestramento:
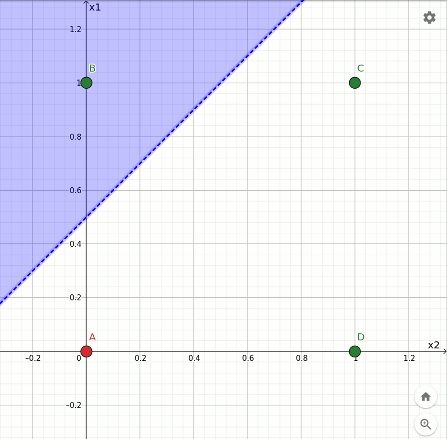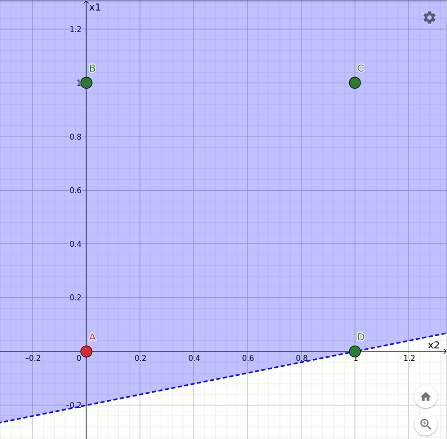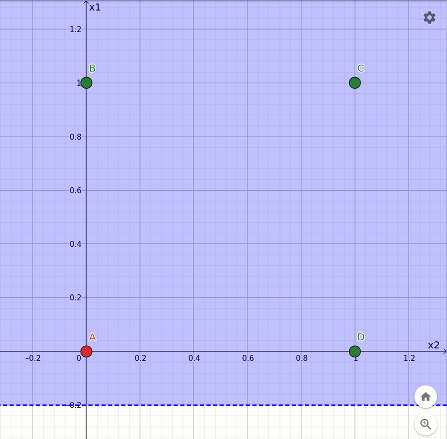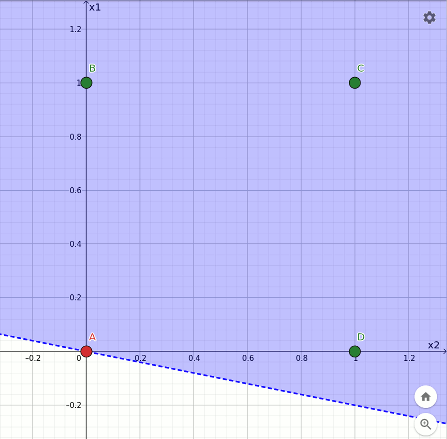
Rappresentazione geometrica dell'apprendimento della funzione or.
Si può notare che nella configurazione finale solamente i punti evidenziati in verde ricadono nell'area azzurra; quello rosso cade esattamente sul confine che però non fa parte della superficie colorata.
L'animazione che segue mostra la traiettoria del taglio nella transizione dalla funzione or alla funzione and, avvenuto in 4 epoche a partire dalla configurazione finale dell'or. In questo caso la separazione è ancora più evidente:
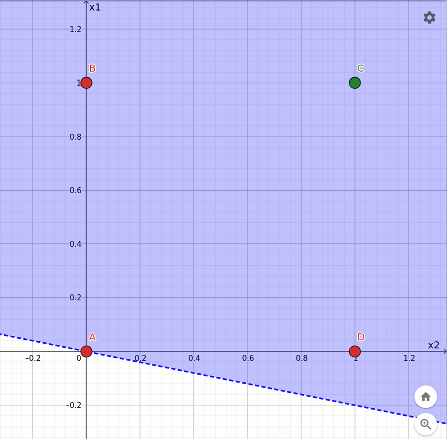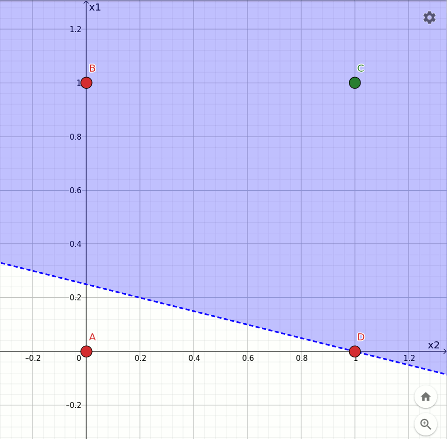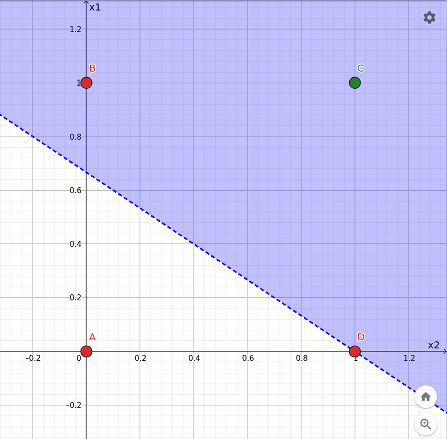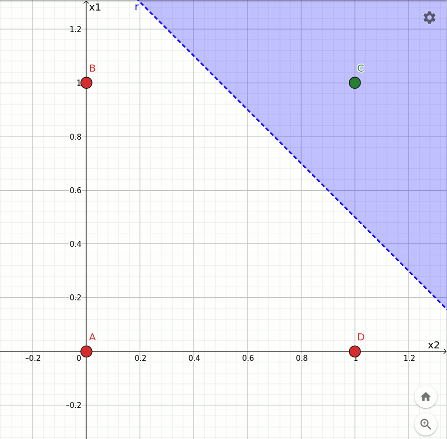
Rappresentazione geometrica dell'apprendimento della funzione and.
L'ultima sequenza mostra la rotazione avvenuta durante l'apprendimento della funzione not x1 a partire dall'and. Anche in questo caso un punto rosso finisce sul confine:
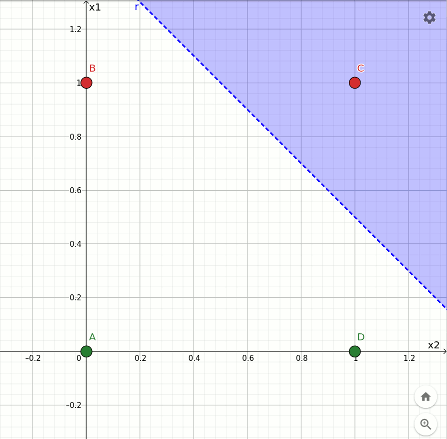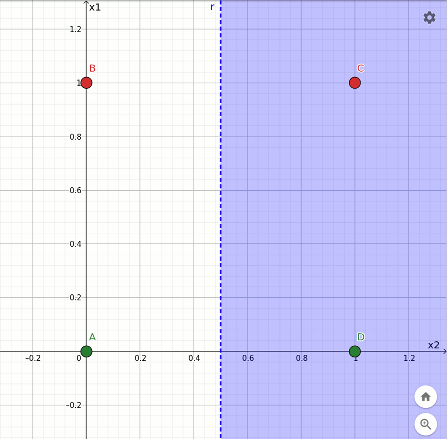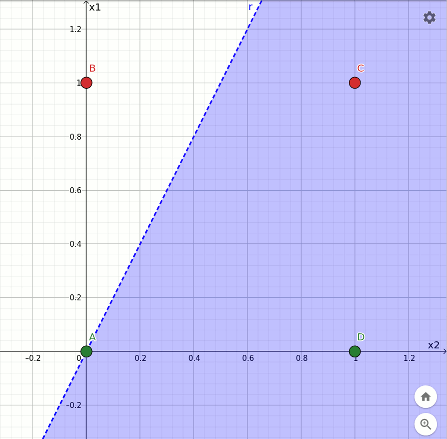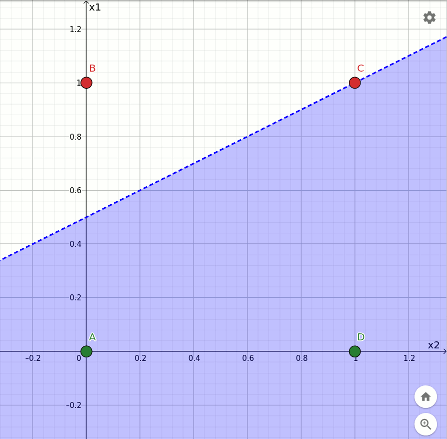
Rappresentazione geometrica dell'apprendimento della funzione not x1.
L'interpretazione geometrica dell'effetto dell'apprendimento aiuta a comprendere i limiti del percettrone, in particolare in relazione all'impossibilità di replicare la funzione xor per il fatto che i punti B e D non sono separabili dai punti A e C mediante una linea. Il percettrone questo non lo sa e continua imperterrito a modificare i pesi e la soglia nella vana speranza di trovare un taglio con tali caratteristiche.
Il programma del percettrone binario è scaricabile qui.
La medesima versione è disponibile anche on-line sul portale ufficiale di Scratch all'indirizzo https://scratch.mit.edu/projects/549325647 e direttamente integrata in questa pagina qui sotto:
L'apprendimento del percettrone binario è avvenuto presentando una dopo l'altra tutte le possibili configurazioni degli stimoli in ingresso. Il percettrone è però anche in grado di classificare stimoli che non ha mai visto prima. Per dimostrare questa capacità lo si mette alla prova con l'iris dataset, un catalogo di 150 misure relative a tre diverse specie di iris compilato dal botanico Edgar Anderson nel 1936 (una copia locale è disponibile qui). L'addestramento avverrà utilizzando solo una parte dei dati disponibili; quelli rimanenti verranno utilizzati per la sua validazione.
L'iris dataset contiene, per ognuna delle tre specie setosa, versicolor e virginica, lunghezza e larghezza del petalo e del sepalo del fiore di 50 piante diverse. Questo esperimento si concentra sulle dimensioni del petalo, associando allo stimolo x1 la sua lunghezza, allo stimolo x2 la sua larghezza. Gli stimoli non sono più binari ma numeri in virgola mobile nell'intervallo 0÷8 e 0÷3 rispettivamente.
Avendo a che fare con un discreto numero di possibili configurazioni d'ingresso conviene predisporre una procedura automatica che si occupi dell'apprendimento. A tale scopo vengono introdotte tre nuove variabili: lengths, che contiene l'elenco delle lunghezze dei petali utilizzati durante l'addestramento, widths che contiene la loro larghezza, responses che contiene la risposta attesa dal sistema. Il codice effettua un numero arbitrario di cicli di addestramento presentando i valori di lunghezza e larghezza di un petalo al percettrone e attivando la procedura di apprendimento qualora la specie proposta dal sistema non corrisponda a quella attesa. Il codice tiene anche il conto degli errori commessi:
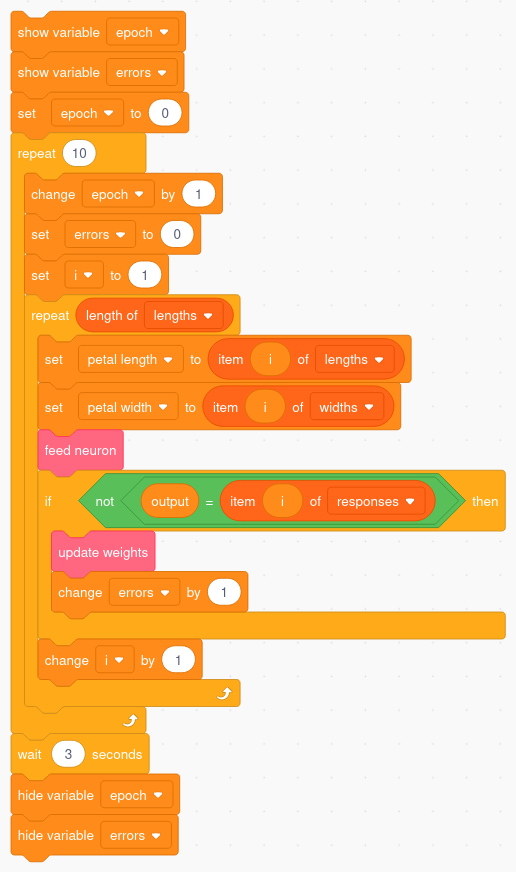
Il codice per l'addestramento automatico.
Per addestrare il percettrone a distinguere i fiori setosa da quelli versicolor è necessario individuare il cosiddetto training set, in questo caso una decina di fiori di ognuna delle due specie con la relativa classificazione:
| # | lunghezza | larghezza | setosa? |
|---|---|---|---|
| 1 | 1.4 | 0.2 | 1 |
| 6 | 1.7 | 0.4 | 1 |
| 14 | 1.1 | 0.1 | 1 |
| 25 | 1.9 | 0.2 | 1 |
| 27 | 1.6 | 0.4 | 1 |
| 36 | 1.2 | 0.2 | 1 |
| 37 | 1.3 | 0.2 | 1 |
| 44 | 1.6 | 0.6 | 1 |
| 45 | 1.9 | 0.4 | 1 |
| 46 | 1.4 | 0.3 | 1 |
| 53 | 4.9 | 1.5 | 0 |
| 54 | 4.0 | 1.3 | 0 |
| 61 | 3.5 | 1.0 | 0 |
| 64 | 4.7 | 1.4 | 0 |
| 68 | 4.1 | 1.0 | 0 |
| 74 | 4.7 | 1.2 | 0 |
| 78 | 5.0 | 1.7 | 0 |
| 83 | 3.9 | 1.2 | 0 |
| 87 | 4.7 | 1.5 | 0 |
| 99 | 3.0 | 1.1 | 0 |
Training set per il classificatore setosa/versicolor.
Nota: la prima colonna riporta l'indice del dato all'interno del dataset originale.
Una volta copiato il contenuto della tabella nelle tre variabili lista prima citate si fa partire l'addestramento (qui una versione del progetto con i dati di addestramento precaricati). Già dopo i primi due cicli di apprendimento il percettrone non commette più alcun errore. L'efficacia del classificatore si conferma sottoponendo i dati di altri petali non facenti parte del training set. Il diagramma sottostante, ove la lunghezza dei petali è riportata in ascissa e la loro larghezza in ordinata, mostra la distribuzione dei petali setosa in blu e quelli versicolor in rosso. I punti con diametro maggiore sono quelli utilizzati durante l'apprendimento:
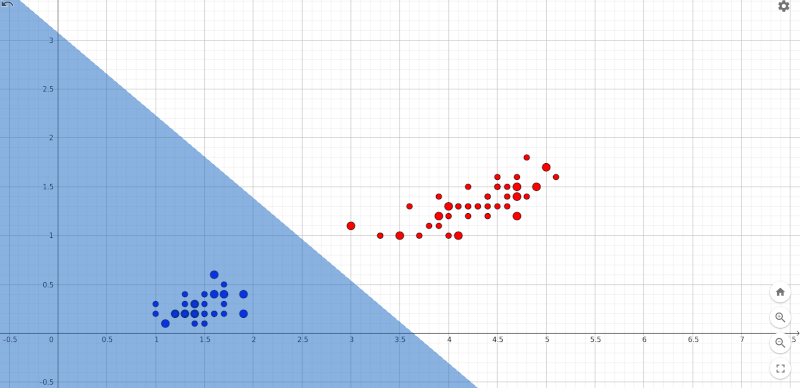
La classificazione dei fiori setosa e versicolor.
La distribuzione spaziale dei due insiemi li rende linearmente separabili e ciò consente al percettrone di individuare in breve tempo una retta che li pone in due regioni del piano separate.
Si vuole ottenere un classificatore che distingua i fiori versicolor da quelli virginica. I dati scelti per l'addestramento sono i seguenti:
| # | lunghezza | larghezza | versicolor? |
|---|---|---|---|
| 53 | 4.9 | 1.5 | 1 |
| 54 | 4.0 | 1.3 | 1 |
| 61 | 3.5 | 1.0 | 1 |
| 64 | 4.7 | 1.4 | 1 |
| 68 | 4.1 | 1.0 | 1 |
| 74 | 4.7 | 1.2 | 1 |
| 78 | 5.0 | 1.7 | 1 |
| 83 | 3.9 | 1.2 | 1 |
| 87 | 4.7 | 1.5 | 1 |
| 99 | 3.0 | 1.1 | 1 |
| 101 | 6.0 | 2.5 | 0 |
| 107 | 4.5 | 1.7 | 0 |
| 108 | 6.3 | 1.8 | 0 |
| 114 | 5.0 | 2.0 | 0 |
| 118 | 6.7 | 2.2 | 0 |
| 122 | 4.9 | 2.0 | 0 |
| 125 | 5.7 | 2.1 | 0 |
| 127 | 4.8 | 1.8 | 0 |
| 135 | 5.6 | 1.4 | 0 |
| 145 | 5.7 | 2.5 | 0 |
Training set per il classificatore versicolor/virginica.
Una versione del progetto con i dati del classificatore precaricati è disponibile qui.
In questo caso l'algoritmo di apprendimento non converge. Prolungare l'addestramento a 100, 200, o 500 epoche non serve, il percettrone commette sempre almeno un errore di classificazione. La ragione è subito chiara se si considera la distribuzione spaziale dei dati, qui sotto riportati assieme alla posizione assunta dal taglio dopo 100 epoche:
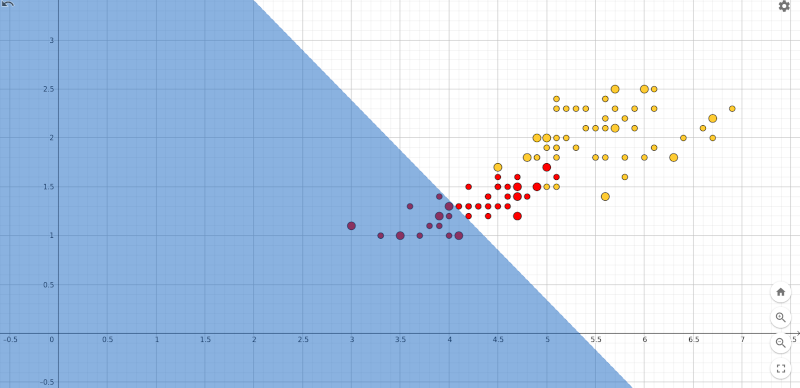
La classificazione dei fiori versicolor e virginica dopo 100 epoche.
Non c'è speranza di convergenza perché i due insiemi non sono linearmente separabili.
Il percettrone è in grado di discriminare gli stimoli che riceve se questi sono linearmente separabili. Per semplicità sono stati presentati due esempi bi-dimensionali, ma la stessa considerazione vale anche nel caso generale in cui il percettrone è dotato di più di due ingressi.
La rapidità con cui il percettrone determina il criterio discriminante, il cosiddetto “taglio”, dipende dal numero e dalla tipologia di esempi usati nell'addestramento e dal valore assegnato al tasso di apprendimento η. Non esistono indicazioni di validità generale, le scelte ottimali sono spesso dettate dall'esperienza.
Un possibile problema che è stato del tutto trascurato riguarda la stabilità numerica dell'algoritmo di apprendimento, ovvero l'assicurarsi che i pesi e la soglia non assumano valori estremamente piccoli o estremamante grandi.
Le classificazioni che il percettrone non è stato in grado di individuare, lo xor e la distinzione versicolor/virginica, viene correttamente trattato da una struttura di neuroni stratificati nota come percettrone multi-strato. La presenza di più neuroni permette di tracciare dei tagli curvilinei, ma richiede la definizione di algoritmi di apprendimento più complicati.
Il percettrone multi-strato infine è solo una delle possibili forme di rete neurale artificiale, negli anni ne sono state definite di svariate:
Click sull'immagine per ingrandirla.
Pagina modificata il 08/06/2021